As explained in our June 18 blog, JEB2 architecture and back-end API allows the development of third-party code: Plugins such as disassemblers, decompilers, parsers, or else, can be easily integrated to provide analysis capability for virtually any type of data.
We have been working on proof-of-concepts plugins for various file formats internally, such as:
An Adobe PDF file format plugin. The plugin provides deep PDF view and navigation, anomaly detection, binary correspondence, and more. Coupled with other JEB2 analysis plugins (such as a JavaScript beautifier plugin), that makes for a powerful PDF reverse-engineering tool:
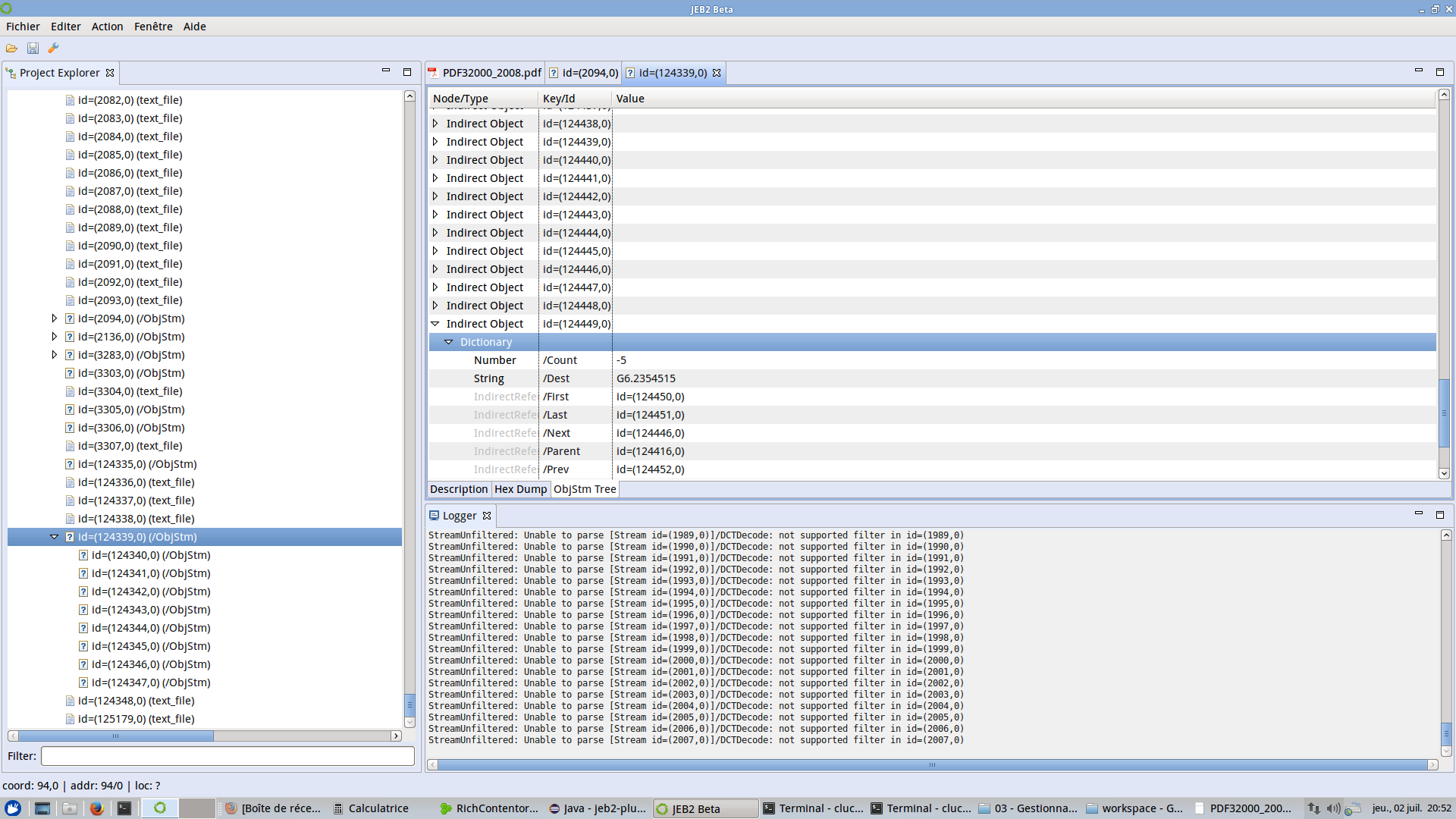
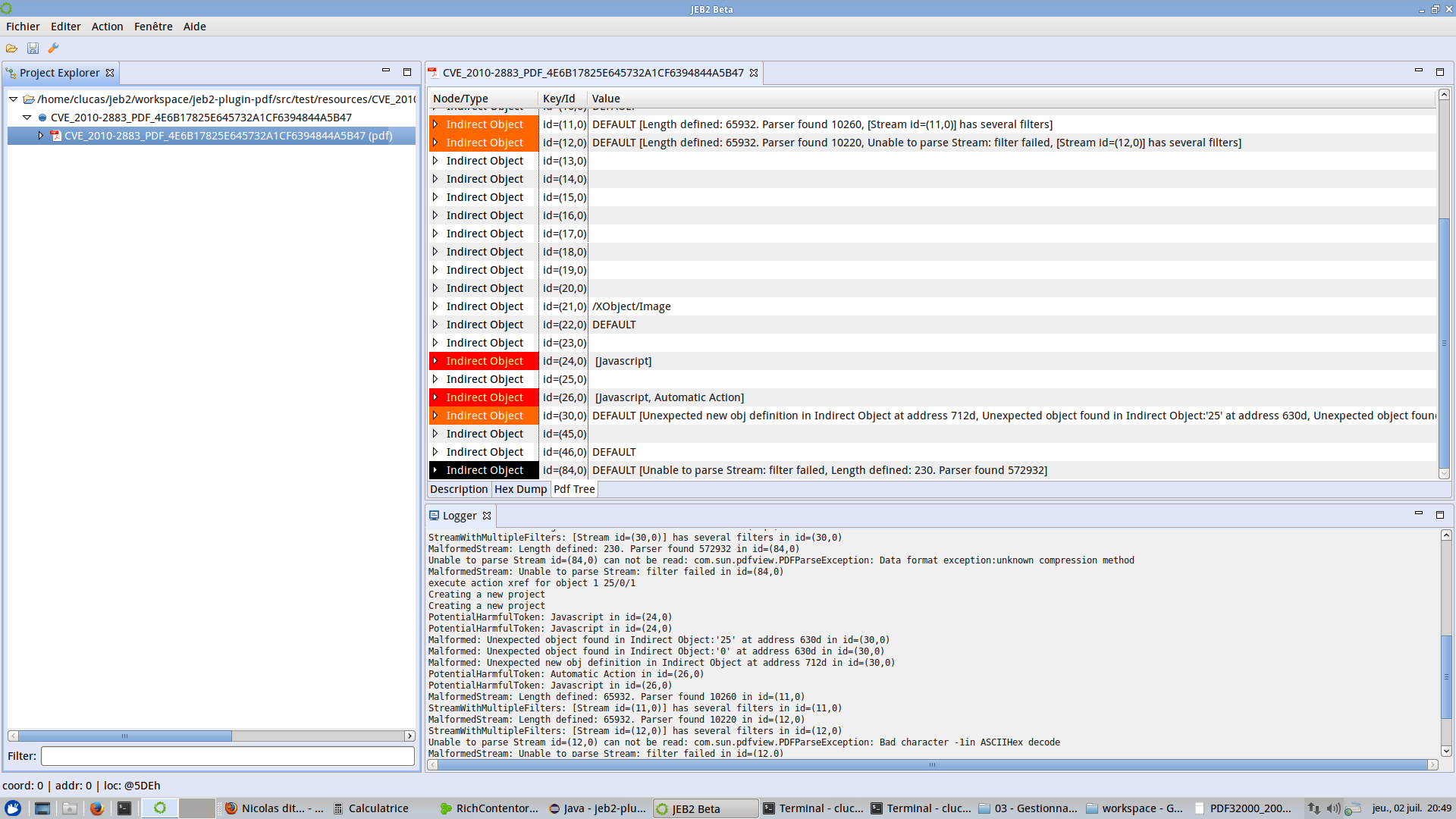
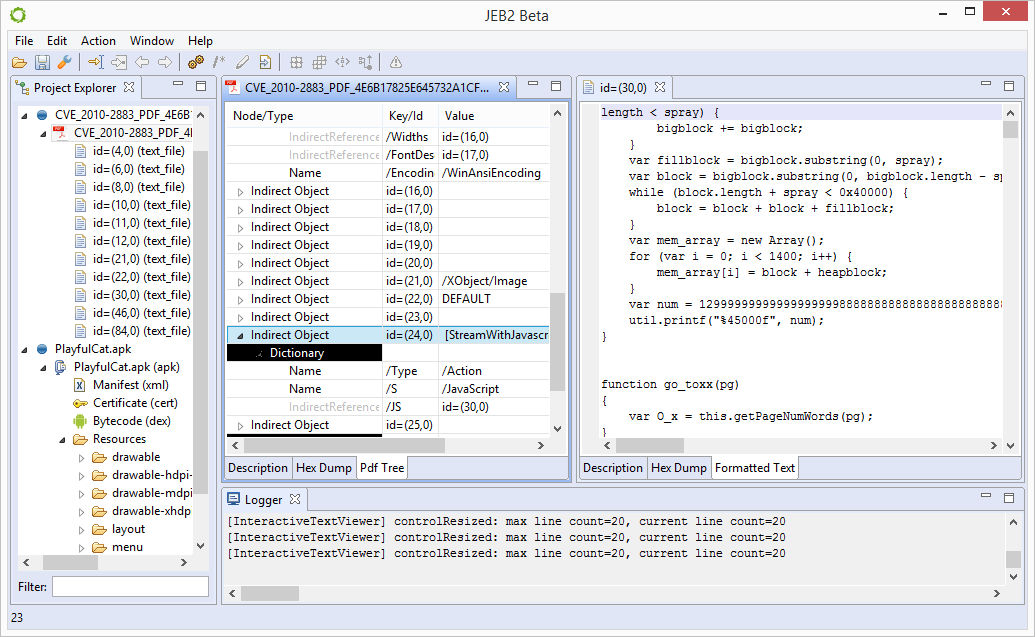
A Microsoft Compound File / OLE file, for various document types, such as Excel in the pictures below:
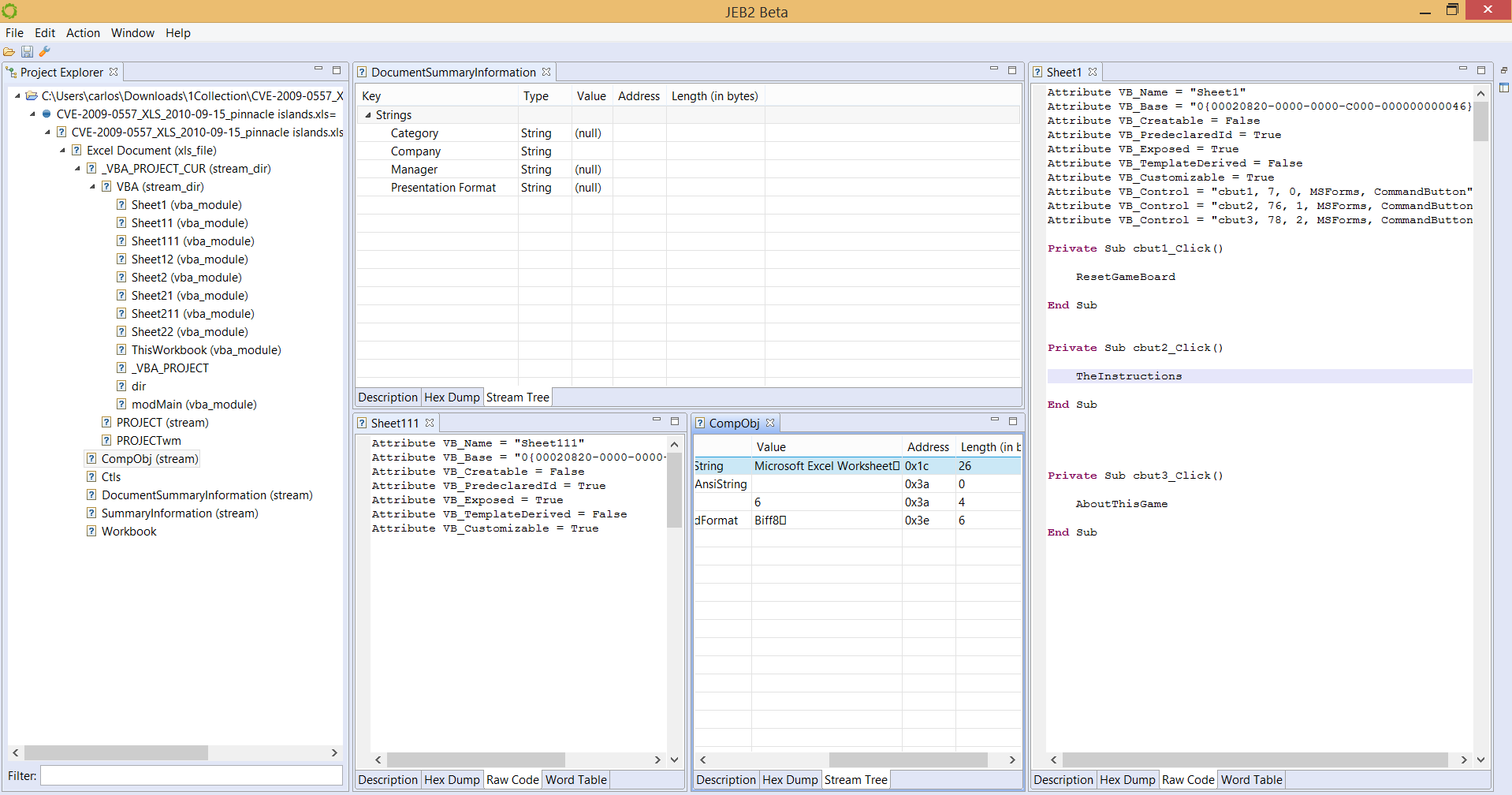
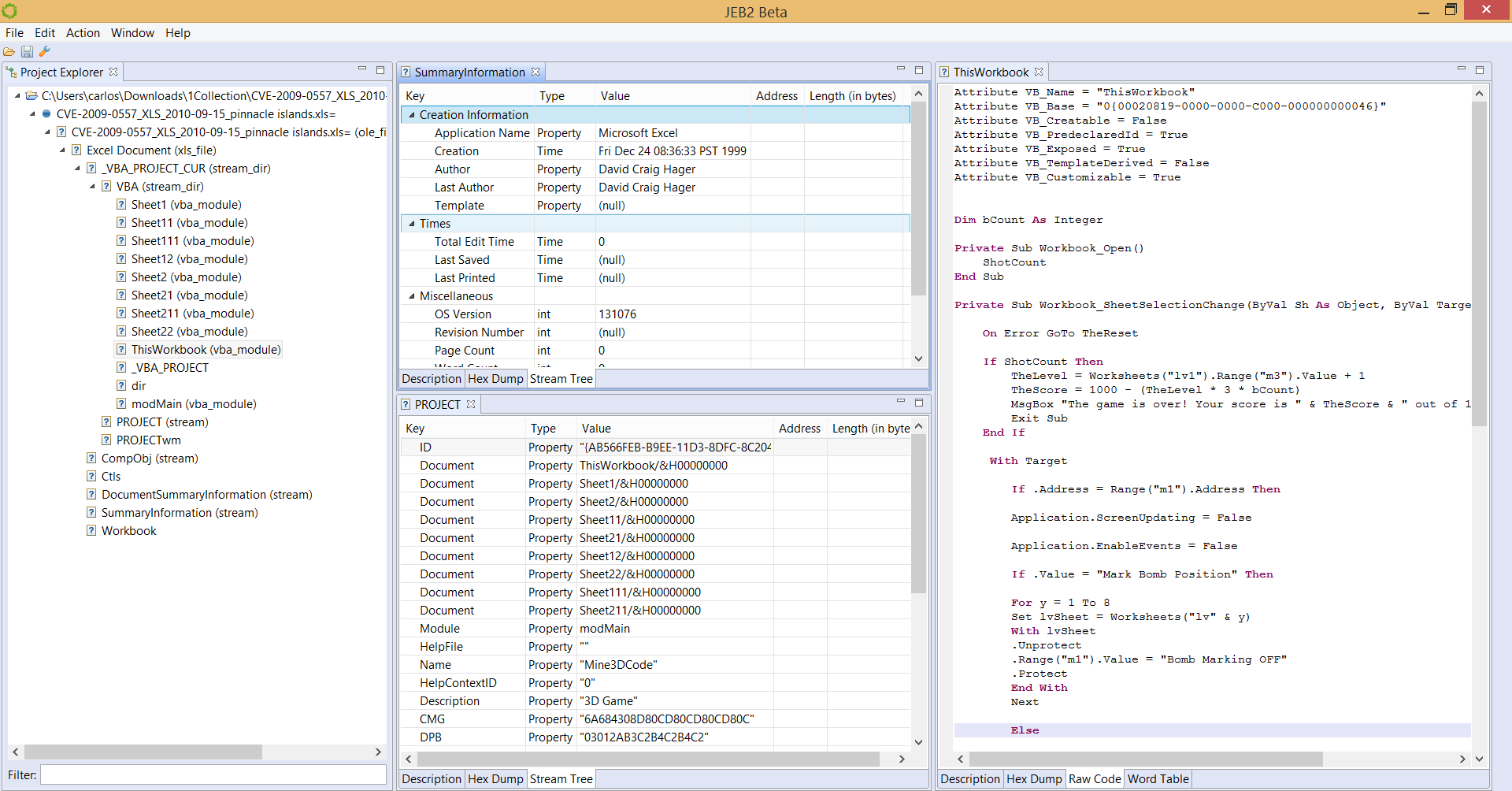
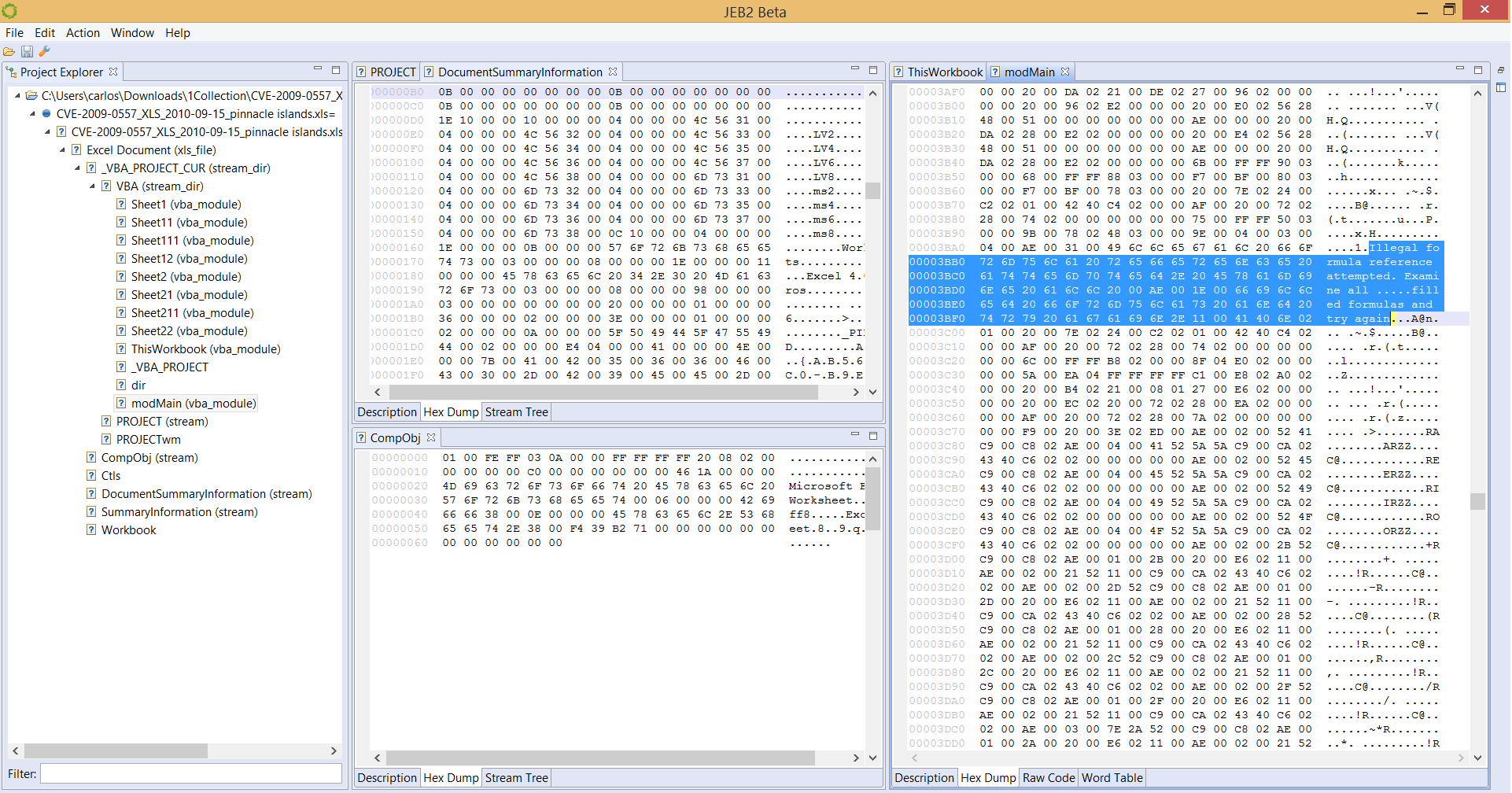
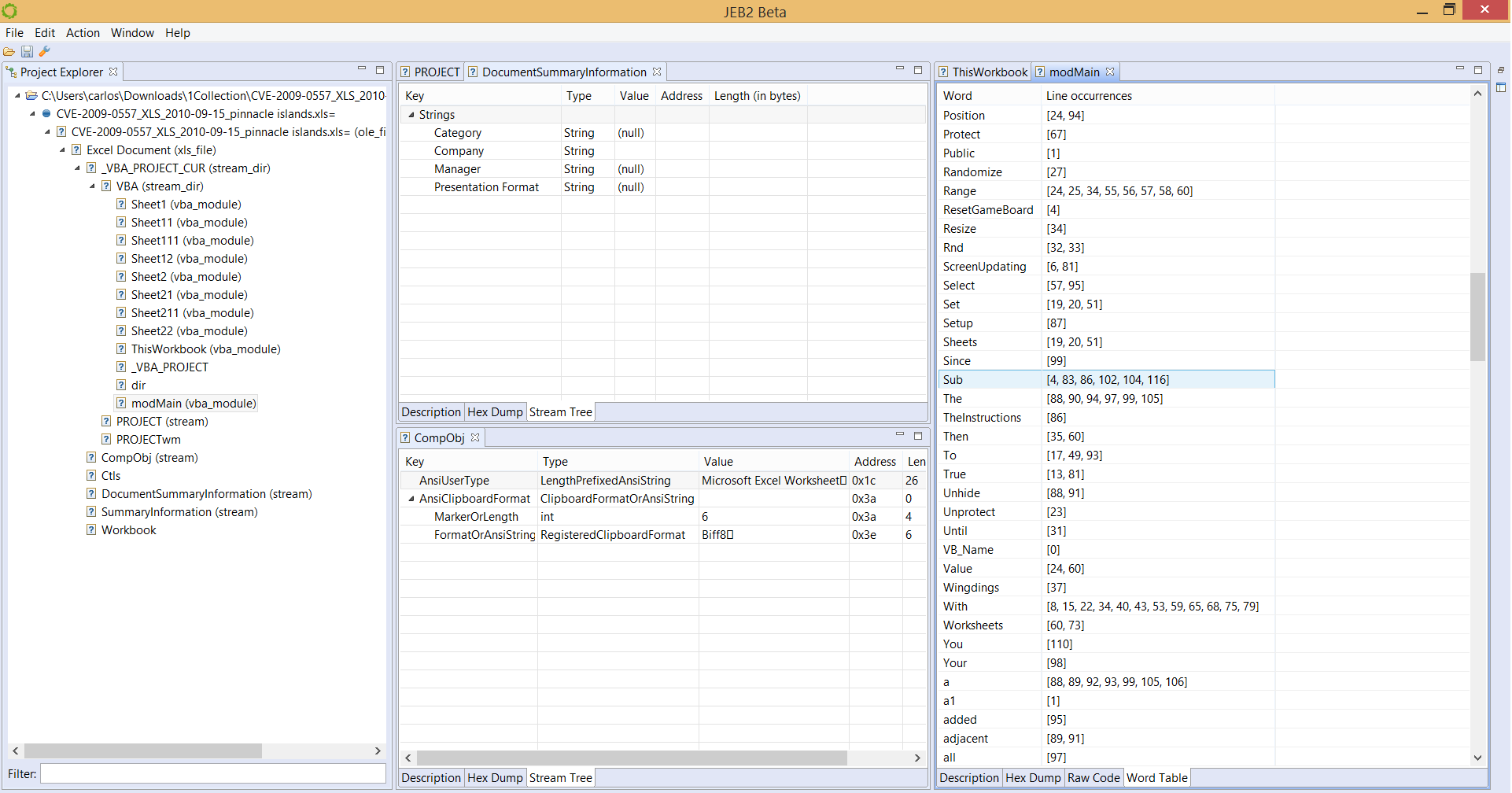
We also have plugins for ELF object files, MIPS machine code, Android OAT resource extraction, ETC1 image reconstruction, etc.
Plugins can work on several types of input, including the output of other plugins, for recursive and deep analysis in artifact data. We are planning to open up the back-end API shortly after the full versions release, which will happen in mid July.
Some of those plugins will be open-source, we hope they provide great tutorials and insights into plugins writing for the JEB2 back-end API.
One thought on “JEB2 plugins for document formats”