This blog assumes that JEB version 2.1.0 or above is used along with the OAT plugin 1.0.2 or above.
Parsing support for optimized DEX files was added to JEB2 to allow the analysis of non-deodex’ed files. Since ODEX files are target-dependant, the executing Dalvik VM is no longer restricted to regular opcodes. ODEX files may make use of “illegal” opcodes, optimized opcodes, or even the once regular but now dead extended opcodes. Whenever possible, parsing will take place, and instructions displayed in the assembly view.
In the screenshot below, note that opcode 43h (illegal for non-optimized code) is used, as well as iput-wide-volatile (optimized opcode for field access).
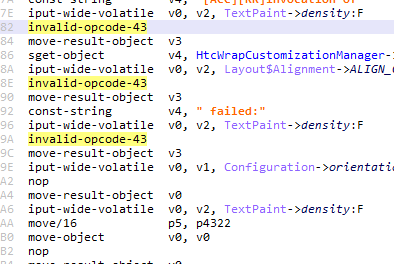
In that second screenshot, notice the use of a non-standard jumbo opcode.

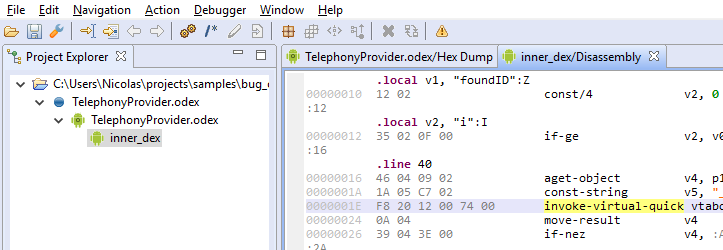
If you are analyzing an extracted ODEX file (one whose header bytes start with “dey\n”), then all versions of JEB2 shall be able to process it. The Project tree will look like the following (project > artifact > odex unit > dex unit):
If you are analyzing an OAT file (DEX file precompiled to native and ready to run within the ART runtime), then you will need one additional plugin: the OAT plugin. This plugin can be registered on Business and Enterprise versions of JEB2. (Note: older versions of JEB 2.0, mainly versions 2.0.12 and above, require the third-party ELF plugin as well.)
Installation steps:
- Visit our public GitHub account
- Download the latest package of the OAT plugin
- Drop the JAR file in the coreplugins folder within your JEB2 installation directory
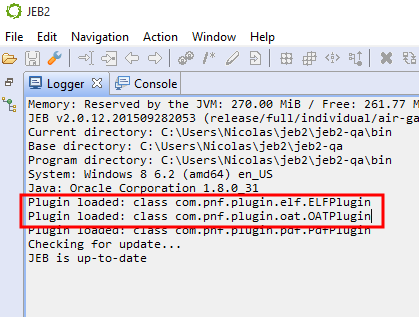
- Restart JEB2. The lines “Plugin loaded … OATPlugin” should be visible in the console
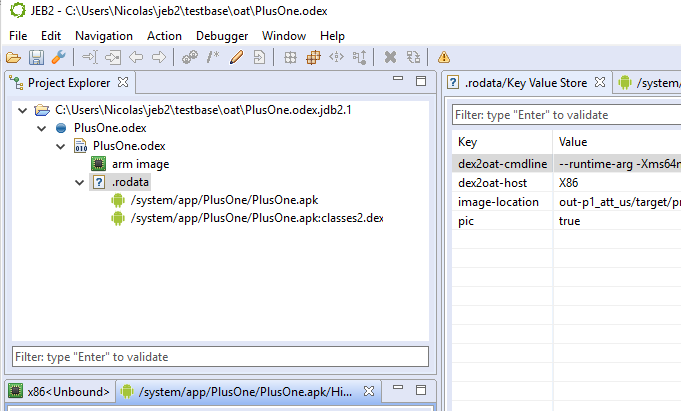
Now, you may open an OAT file. The project view should be similar to the following (project > artifact > elf unit > oat unit > dex or odex unit):
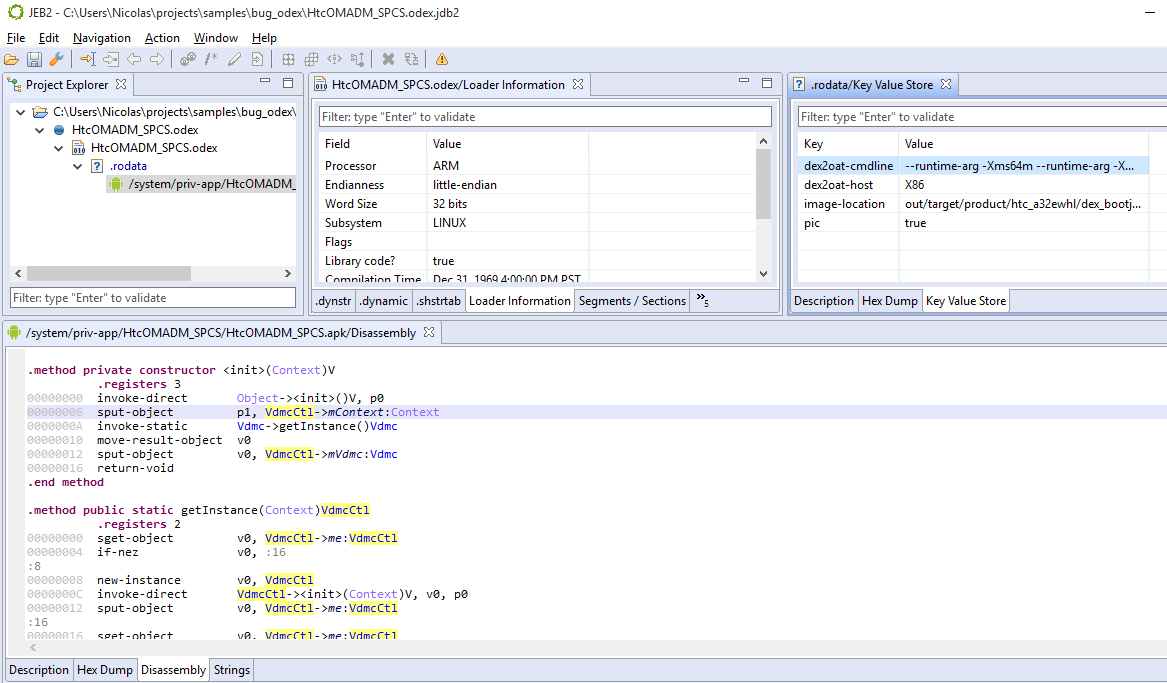
Here is another example of an ELF file containing an OAT section, containing 2 optimized DEX files:
That is it for this blog post. We are planning to release more documentation and tutorials about our APIs In the coming days. In the meantime, remember to check our open-source plugins on GitHub, they are great starting points for anyone interested in writing their own parsers or back-end plugins. Stay tuned, and happy analysis.